-
학원 day39. 분석함수, 집합 연산, 계층형 쿼리기록 2022. 10. 31. 11:50
Top-N 분석
: 조건에 맞는 최상위 레코드 N개 혹은 최하위 레코드 N개를 조회하는 쿼리
( 예시 : 급여를 가장 많이 받는 사원 3명, 판매가 가장 많이 된 도서 10종류 조회 )
ROWNUM 의사컬럼 사용하기
: ROWNUM은 조회된 행에 행번호를 1번부터 순서대로 부여하는 의사컬럼이다.
* 형식
SELECT ROWNUM, COLUMN1, COLUMN2, COLUMN3, ...
FROM (SELECT COLUMN1, COLUMN2, COLUMN3, ...
FROM 테이블명
ORDER BY 분석대상컬럼명 정렬기준)
WHERE ROWNUM <= N;
-- 급여를 가장 많이 받는 사원 3명을 조회하기 SELECT ROWNUM, EMPLOYEE_ID, FIRST_NAME, SALARY FROM (SELECT EMPLOYEE_ID, FIRST_NAME, SALARY FROM EMPLOYEES ORDER BY SALARY DESC) WHERE ROWNUM <= 3; -- 가장 최근에 입사한 직원 10명 조회하기 SELECT ROWNUM, EMPLOYEE_ID, FIRST_NAME, HIRE_DATE FROM (SELECT EMPLOYEE_ID, FIRST_NAME, HIRE_DATE FROM EMPLOYEES ORDER BY HIRE_DATE DESC) WHERE ROWNUM <= 10;
그런데, 최상위, 최하위 레코드 N개가 아닌 중간 순위를 알고 싶을 때 분석 함수라는 것을 쓴다.분석 함수
: 테이블의 데이터를 특정 기준으로 분석하여 결과를 조회하는 함수
* 순위 분석함수 : RANK(), DENSE_RANK(), ROW_NUMBER() (ROW_NUMBER()를 가장 많이 사용!)
- RANK나 DENSE_RANK는 순위에 다른 조회 갯수가 가변적이다. (10위까지 조회했을 때 조회결과가 10개 이상일 수 있다. 동점자가 있을 수 있어서)
- ROW_NUMBER는 순위에 따른 조회 갯수가 가변적이지 않다. (10위까지 조회했을 때 조회결과가 항상 10개이다.)
* 집계 분석함수 : SUM(), MIN(), MAX(), AVG(), COUNT() (분석함수이면서 그룹함수)
* 형식 ([]는 생략가능)
SELECT 분석함수([컬럼명]) OVER ([PARTITION BY 컬럼명] [ORDER BY 컬럼명 정렬기준])
FROM 테이블명
★ ROW NUMBER를 이용해서 중간 순위 조회하기
SELECT ROWNUMBER, COLUMN1, COLUMN2, COLUMN3 ...
FROM (SELECT ROW_NUMBER() OVER (ORDER BY 분석컬럼명 정렬기준) ROWNUMBER, -- ROW_NUMBER()가 분석함수이고, OVER는 앞에가 분석함수임을 알려준다.
COLUMN1, COLUMN2, COLUMN3, ...
FROM 테이블명
WHERE 조건식) -- 정렬해서 번호까지 부여된 상태
WHERE ROWNUMBER BETWEEN 11 AND 20;
-- 급여를 기준으로 직원들을 정렬했을 때 급여 순위가 1 ~ 10에 해당하는 직원 10명을 조회하기 SELECT ROWNUMBER, EMPLOYEE_ID, FIRST_NAME, SALARY FROM (SELECT ROW_NUMBER() OVER (ORDER BY SALARY DESC) ROWNUMBER, EMPLOYEE_ID, FIRST_NAME, SALARY FROM EMPLOYEES) WHERE ROWNUMBER >= 1 AND ROWNUMBER <= 10; -- 급여를 기준으로 직원들을 정렬했을 대 급여 순위가 11 ~ 20에 해당하는 직원 10명을 조회하기 SELECT ROWNUMBER, EMPLOYEE_ID, FIRST_NAME, SALARY FROM (SELECT ROW_NUMBER() OVER (ORDER BY SALARY DESC) ROWNUMBER, EMPLOYEE_ID, FIRST_NAME, SALARY FROM EMPLOYEES) WHERE ROWNUMBER >= 11 AND ROWNUMBER <= 20; -- 급여를 기준으로 순위 분석함수를 사용해서 조회하기 SELECT RANK() OVER (ORDER BY SALARY DESC) SALARY_RANKING, -- 같은 순위가 여러 개 나올 수 있다. DENSE_RANK() OVER (ORDER BY SALARY DESC) SALARY_DENSE_RANKING, -- 같은 순위가 여러개 나오고 그 다음 순위가 나옴 ROW_NUMBER() OVER (ORDER BY SALARY DESC) SALARY_ROW_NUMBER, -- 내가 조회하려는 갯수만큼 나온다. EMPLOYEE_ID, FIRST_NAME, SALARY FROM EMPLOYEES;-> 급여를 기준으로 순위 분석함수를 사용해서 조회하기 결과

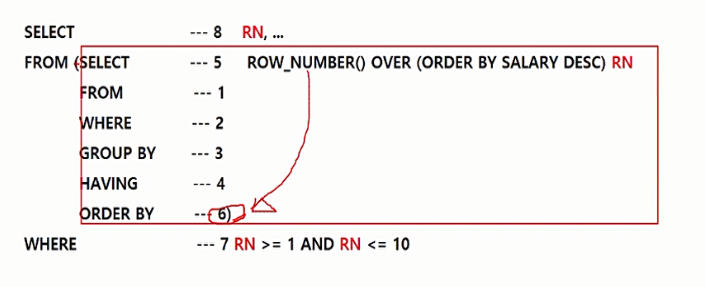
★ SQL 실행 순서
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY 순
PARTITION BY를 이용해서 부서별로 순위 부여하기
-- 부서별로 구분해서(PARTITION BY DEPARTMENT_ID) 해당 부서내에서 급여를 기준으로 순위를 부여하기 (계산 대상 그룹화) SELECT ROW_NUMBER() OVER (PARTITION BY DEPARTMENT_ID ORDER BY SALARY DESC) ROWNUMBER, EMPLOYEE_ID, FIRST_NAME, SALARY FROM EMPLOYEES ORDER BY DEPARTMENT_ID, ROWNUMBER;
그룹함수와 분석함수
* 그룹함수 : 테이블 전체 혹은 집합 그룹당 결과가 하나 반환된다.
SELECT SUM(컬럼명)
FROM EMPLOYEES
* 분석함수 : 행 마다 결과가 반환된다.
SELECT SUM(컬럼명) OVER()
FROM EMPLOYEES-- 집계 분석함수를 사용해서 직원정보와 각 부서별 평균급여를 조회하기 SELECT DEPARTMENT_ID, EMPLOYEE_ID, FIRST_NAME, SALARY, AVG(SALARY) OVER(PARTITION BY DEPARTMENT_ID) FROM EMPLOYEES; -- 집계 분석함수를 사용해서 직원정보와 해당 직원이 소속된 부서의 사원수, 총급여, 평균급여를 조회하기 SELECT DEPARTMENT_ID, EMPLOYEE_ID, FIRST_NAME, SALARY, COUNT(SALARY) OVER (PARTITION BY DEPARTMENT_ID) CNT, SUM(SALARY) OVER (PARTITION BY DEPARTMENT_ID) SALARY_SUM, TRUNC(AVG(SALARY) OVER (PARTITION BY DEPARTMENT_ID)) SALARY_AVERAGE FROM EMPLOYEES; -- 직원아이디, 이름, 급여, 부서 평균 급여, 직원급여와 부서평균급여 차이를 조회하기(집계 분석함수 사용) SELECT EMPLOYEE_ID, FIRST_NAME, SALARY, TRUNC(AVG(SALARY) OVER (PARTITION BY DEPARTMENT_ID)) SALARY_AVG, TRUNC(SALARY - AVG(SALARY) OVER (PARTITION BY DEPARTMENT_ID)) SALARY_GAP FROM EMPLOYEES ORDER BY EMPLOYEE_ID; -- 직원아이디, 이름, 급여, 부서 평균 급여, 직원급여와 부서평균급여 차이를 조회하기 (인라인뷰 사용) SELECT B.EMPLOYEE_ID, B.FIRST_NAME, B.SALARY, A.AVG_SALARY, TRUNC(B.SALARY - A.AVG_SALARY) SALARY_GAP FROM (SELECT DEPARTMENT_ID, TRUNC(AVG(SALARY)) AVG_SALARY FROM EMPLOYEES GROUP BY DEPARTMENT_ID) A, EMPLOYEES B WHERE A.DEPARTMENT_ID = B.DEPARTMENT_ID ORDER BY B.EMPLOYEE_ID;
집합 연산자
: 2개 이상의 SQL문 실행결과에 대한 집합연산 (합집합, 교집합, 차집합)를 지원한다.* 조건
- SQL문의 컬럼 갯수가 동일해야 한다. (NULL, ' ' 활용 가능)
- SQL문의 컬럼의 데이터타입이 동일해야 한다.
- SQL문의 각 컬럼별 이름이 동일할 필요는 없다.

-------------------------------------------------------------------------------- -- 집합 연산자 : 2개 이상의 SQL문 실행결과에 대한 집합연산 (합집합, 교집합, 차집합)를 지원한다. -------------------------------------------------------------------------------- -- EMPLOYEES 테이블과 JOB_HISTORY 테이블 : 직종이 변경된 적이 있는 직원의 아이디를 조회하기 -- EMPLOYEES 테이블에서 조회한 결과와 JOB_HISTORY 테이블에서 조회한 결과에 모두 포함된 값을 조회한다.(교집합) SELECT EMPLOYEE_ID FROM EMPLOYEES INTERSECT SELECT EMPLOYEE_ID FROM JOB_HISTORY; -- EMPLOYEES 테이블과 JOB_HISTORY 테이블 : 직종이 한번도 변경된 적이 없는 직원의 아이디, 이름, 급여를 조회하기 -- EMPLOYEES 테이블의 조회결과에서 JOB_HISTORY 테이블의 조회결과를 제외한 값을 조회한다.(차집합) SELECT EMPLOYEE_ID, FIRST_NAME, SALARY FROM EMPLOYEES WHERE EMPLOYEE_ID IN (SELECT EMPLOYEE_ID FROM EMPLOYEES MINUS SELECT EMPLOYEE_ID FROM JOB_HISTORY); SELECT A.EMPLOYEE_ID, B.FIRST_NAME, B.SALARY FROM (SELECT EMPLOYEE_ID FROM EMPLOYEES MINUS SELECT EMPLOYEE_ID FROM JOB_HISTORY) A, EMPLOYEES B WHERE A.EMPLOYEE_ID = B.EMPLOYEE_ID ORDER BY A.EMPLOYEE_ID;- 직원들의 매니저 혹은 부서의 매니저 조회하기

=> UNION ALL과 UNION의 차이 : UNION은 이미 있는 MANAGER_ID값은 뺀다.
계층 검색
: 계층형 쿼리를 이용해서 트리 구조로 데이터를 조회하는 것
: 조직도, 메뉴, 카테고리 등은 대부분 트리구조를 가지고 있다.
계층 검색의 예
- 특정 데이터의 하위 데이터를 조회하기
- 특정 데이터의 상위 데이터를 조회하기
계층형 쿼리의 형식
SELECT [LEVEL, ] COLUMN, COLUMN, ...
FROM 테이블
[WHERE 조건식]
START WITH 조건식
CONNECT BY PRIOR 조건식
* LEVEL : 조회되는 각 행에 대한 레벨을 반환한다. 최상위행은 1, 그 하위행은 2, 그 하위의 하위행은 3을 반환한다.
* START WITH 조건식 : 계층 검색의 시작지점을 지정한다.
* CONNECT BY : 상위행, 하위행 간의 관계를 지정한다.-- 상위행에서 하위행으로 검색하기 -- SELECT LEVEL, 컬럼명, 컬럼명 -- FROM 테이블 -- START WITH 조건식 -- CONNECT BY PRIOR 부모컬럼(기본키) = 자식컬럼(외래키) -- 100번 직원의 부하직원을 조회하기 SELECT LEVEL, EMPLOYEE_ID, FIRST_NAME, MANAGER_ID FROM EMPLOYEES START WITH EMPLOYEE_ID = 100 CONNECT BY PRIOR EMPLOYEE_ID = MANAGER_ID;< 100번 직원의 부하직원 조회 결과 >

-- 101번 직원의 부하직원을 조회하기 SELECT LEVEL, EMPLOYEE_ID, FIRST_NAME, MANAGER_ID FROM EMPLOYEES START WITH EMPLOYEE_ID = 101 CONNECT BY PRIOR EMPLOYEE_ID = MANAGER_ID; SELECT LEVEL, EMPLOYEE_ID, LPAD(' ', (LEVEL-1)*5, ' ') || FIRST_NAME, MANAGER_ID FROM EMPLOYEES START WITH EMPLOYEE_ID = 101 CONNECT BY PRIOR EMPLOYEE_ID = MANAGER_ID;< 101번 직원의 부하직원 조회 결과 >

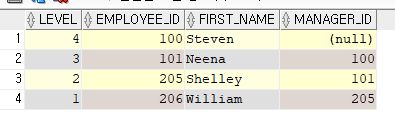
-- 하위행에서 상위행으로 검색하기 -- SELECT LEVEL, 컬럼명, 컬럼명 -- FROM 테이블 -- START WITH 조건식 -- CONNECT BY PRIOR 자식컬럼(외래키 컬럼) = 부모컬럼(기본키 컬럼) -- 206직원의 상관을 조회하기 SELECT LEVEL, EMPLOYEE_ID, FIRST_NAME, MANAGER_ID FROM EMPLOYEES START WITH EMPLOYEE_ID = 206 CONNECT BY PRIOR MANAGER_ID = EMPLOYEE_ID ORDER BY LEVEL DESC;< 206번 직원의 상관 조회 결과 >
Level과 Connect by 를 이용해서 연속된 숫자, 날짜 생성하기
-------------------------------------------------------------------------------- -- LEVEL과 CONNECT BY를 이용해서 연속된 숫자, 날짜 생성하기 -------------------------------------------------------------------------------- -- 1~12까지 연속된 숫자를 조회하기 SELECT LEVEL FROM DUAL CONNECT BY LEVEL <= 12; -- 2004년에 입사한 직원들의 월별 입사자 수를 조회하기 (입사자가 없는 달은 조회되지 않는다.) SELECT TO_NUMBER(TO_CHAR(HIRE_DATE, 'MM')) MONTHS, COUNT(*) FROM EMPLOYEES WHERE HIRE_DATE >= '2004/01/01' AND HIRE_DATE < '2005/01/01' GROUP BY TO_NUMBER(TO_CHAR(HIRE_DATE, 'MM')) ORDER BY MONTHS; -- 2004년에 입사한 직원들의 월별 입사자 수를 조회하기 (입사자가 없는 달은 0으로 조회된다.) SELECT B.MONTHS, NVL(A.CNT, 0) CNT FROM (SELECT TO_NUMBER (TO_CHAR(HIRE_DATE, 'MM'))MONTHS, COUNT(*) CNT FROM EMPLOYEES WHERE HIRE_DATE >= '2004/01/01' AND HIRE_DATE < '2005/01/01' GROUP BY TO_NUMBER(TO_CHAR(HIRE_DATE, 'MM'))) A, (SELECT LEVEL MONTHS FROM DUAL CONNECT BY LEVEL <= 12) B WHERE A.MONTHS(+) = B.MONTHS ORDER BY B.MONTHS ASC; -- 시작일부터 종료일 사이의 날짜 생성하기 SELECT TO_DATE('2022/10/01') + LEVEL - 1 FROM DUAL -- 오라클에서 제공해주는 1행 1열의 더미테이블 CONNECT BY LEVEL <= TO_DATE('2022/10/31') - TO_DATE('2022/10/01') + 1; SELECT LAST_DAY(SYSDATE) FROM DUAL; -- 지정된 월의 시작일부터 종료일 사이의 날짜 생성하기 SELECT TO_DATE('2022/10/01') + LEVEL - 1 FROM DUAL CONNECT BY LEVEL <= LAST_DAY(TO_DATE('2022/10/01')) - TO_DATE('2022/10/01') + 1; -- 10월달 회원 가입 현황 조회하기 SELECT B.DAY, NVL(A.CNT, 0) CNT FROM (SELECT TO_NUMBER(TO_CHAR(USER_CREATED_DATE, 'DD')) DAY, COUNT(*) CNT FROM SAMPLE_USERS WHERE USER_CREATED_DATE >= '2022/10/01' AND USER_CREATED_DATE <= LAST_DAY(TO_DATE('2022/10/01')) GROUP BY TO_NUMBER(TO_CHAR(USER_CREATED_DATE, 'DD'))) A, (SELECT TO_NUMBER(TO_CHAR(TO_DATE('2022/10/01') + LEVEL - 1, 'DD')) DAY FROM DUAL CONNECT BY LEVEL <= LAST_DAY(TO_DATE('2022/10/01')) - TO_DATE('2022/10/01') + 1) B WHERE A.DAY(+) = B.DAY ORDER BY B.DAY;'기록' 카테고리의 다른 글
학원 day41. 태그(2), 엘리먼트, 폼 (0) 2022.11.02 학원 day40. 웹, HTML, 태그, 속성 (0) 2022.11.01 학원 day37~38. ibatis(2), XML (0) 2022.10.30 학원 day36. ibatis (0) 2022.10.26 학원 day35. 무결성제약조건, 인덱스, 트랜잭션 (0) 2022.10.26