-
학원 DAY28. SQL기록 2022. 10. 15. 08:30
SQL의 종류
DDL(Data Definition Language)
- 데이터 정의 언어
- 데이터베이스의 구조를 정의하는 명령어다.
- 데이터베이스의 주요 객체를 생성,삭제,변경하는 작업 수행한다.
(주요 객체 : 테이블, 뷰, 인덱스, 시퀀스, 동의어, 트리거, 사용자 ...)
- 주요 명령어
CREATE : 새로운 데이터베이스 객체 생성
DROP : 기존 데이터베이스 객체 삭제
ALTER : 기존 데이터베이스 객체 변경
TRUNCATE : 데이터를 되돌릴 수 없도록 제거
DML(Data Manipulation Language)
- 데이터 조작 언어
- 데이터베이스에서 데이터를 추가/조회/변경/삭제하는 작업을 수행한다. (행 단위)
- 주요 명령어
INSERT : 테이블에 새로운 데이터 행을 추가한다.
SELECT : 테이블에서 데이터를 조회한다.
UPDATE : 테이블의 데이터를 변경한다.
DELETE : 테이블에 저장된 특정 데이터 행을 삭제한다.
DCL(Data Control Language)
- 데이터 제어 언어
- 권한제어, 트랜잭션 제어 작업을 수행한다.
- 주요 명령어
GRANT : 특정 사용자에게 특정 작업 수행 권한을 부여
REVOKE : 사용자에게 부여된 권한을 박탈
COMMIT : 트랜잭션을 실행
ROLLBACK : 트랜잭션을 취소
SAVEPOINT : 롤백지점을 설정한다.
데이터 조회 (SELECT)
데이터 조회하기
- 테이블의 모든 행, 모든 컬럼을 조회
SELECT * FROM 테이블명;- 테이블의 모든 행, 특정 컬럼을 조회
SELECT 컬럼명, 컬럼명, ... FROM 테이블명;- 산술식 사용하기
select절, where절, group by절, having절 등에서 산술연산자를 사용할 수 있다.
숫자와 날짜 데이터를 대상으로만 사용할 수 있다.
-- JOBS 테이블의 모든 행을 조회한다, 직종아이디, 최고급여, 최소급여, 최고급여의 갭을 조회하기기 SELECT JOB_ID, MAX_SALARY, MIN_SALARY, MAX_SALARY - MIN_SALARY FROM JOBS; -- EMPLOYEES 테이블의 모든 행을 조회한다. 직원아이디, 이름, 급여, 연봉(연봉은 급여에 12을 곱한 값이다.)을 조회하기 SELECT EMPLOYEE_ID, FIRST_NAME, SALARY, SALARY*12 FROM EMPLOYEES;- 조회하는 컬럼명에 별칭 사용하기
SELECT절과 FROM절에서는 별칭을 정의할 수 있다.
별칭에는 특수문자나 공백이 포함될 수 없음. 특수문자, 공백을 포함하고 있을 때는 " "(쌍따옴표)안에 적는다.
하지만, 보통 두단어 이상 쓸 때는 _(언더바)를 이용해서 적는다. (ex. MAX_SALARY)
별칭이 하필 오라클의 명령어와 같을 때에도 " "(쌍따옴표)로 감싸서 표현해야 한다. (쌍따옴표는 단순한 단어로 인식)
SELECT 컬럼명 as 별칭, 컬럼명 as "별칭", 연산식 as 별칭, ... FROM 테이블명 SELECT 컬럼명 별칭, 컬럼명 "별칭", 연산식 별칭, ... FROM 테이블명산술식이 길수록 알아보기 힘들 수 있으니까 별칭을 붙인다. 컬럼명 뒤에 as를 붙이거나 as없이 한칸 띄워서 별칭을 적는다.
행의 제한 (데이터 필터링)
- WHERE절을 사용한다.
- 제시된 조건식이 참인 행만 조회된다.
SELECT 컬럼명, 컬럼명,.... FROM 테이블 WHERE 조건식;-- EMPLOYEES 테이블에서 직종아이디가 IT_PROG인 직원 아이디, 이름, 입사일, 급여를 조회하기 SeLECT employee_ID, FIRST_NAME, HIRE_DATE, SALARY fROM EMPLOYEES WHErE JOB_ID = 'IT_PROG'; -- EMPLOYEES 테이블에서 100번 직원에게 보고하는 직원의 아이디, 이름, 직종을 조회하기 -- EMPLOYEES 테이블에서 MANAGER_ID가 100인 직원의 아이디, 이름, 직종을 조회하기 SELECT employee_ID, FIRST_NAME, JOB_ID FROM EMPLOYEES WHERE MANAGER_ID = 100;오라클 키워드는 대소문자 상관없지만 값(텍스트)는 반드시 똑같이 적어야 한다.
데이터베이스에서 문자열을 나타낼때 ' ' (홑따옴표)를 쓴다.
- 논리 연산자
- 두 개이상의 조건식으로 데이터를 제한할 수 있다.
- AND, OR, NOT
SELECT 컬럼명, 컬럼명,.... FROM 테이블명 WHERE 조건식 AND 조건식; SELECT 컬럼명, 컬럼명,.... FROM 테이블명 WHERE 조건식 OR 조건식; SELECT 컬럼명, 컬럼명,.... FROM 테이블명 WHERE 조건식 AND (조건식 OR 조건식);- AND와 OR을 같이 써야 할 경우에는 OR조건식은 괄호를 넣어야 한다.
- 기타 연산자
- IS NULL, IS NOT NULL
-> 컬럼의 값이 NULL인 행 혹은 NULL이 아닌 경우 TRUE
SELECT 컬럼명, 컬럼명, .... FROM 테이블명 WHERE 컬럼명 IS NULL SELECT 컬럼명, 컬럼명, .... FROM 테이블명 WHERE 컬럼명 IS NOT NULL;데이터베이스의 NULL은 아직 값이 결정되지 않았다는 것을 의미함.
NULL이 포함된 산술연산의 결과는 항상 NULL이다.
NULL은 비교연산자(=, !=)로 비교할 수 없다.
컬럼의 데이터타입과 상관없이 NULL을 가질 수 있다. (자바에서는 참조변수만 NULL값을 가질 수 있다. 기본자료형은 안됨)
- BETWEEN 하한값 AND 상한값
-> 컬럼의 값이 하한값과 상한값 범위내면 TRUE다.
SELECT 컬럼명, 컬럼명, .... FORM 테이블명 WHERE 컬럼명 BETWEEN 값 AND 값;- IN (값, 값, 값, ...)
-> 컬럼의 값이 제시된 값들 중 하나와 일치하면 TRUE다. ( =비교일 때만 가능)
SELECT 컬럼명, 컬럼명, .... FROM 테이블명 WHERE 컬럼명 IN (값, 값, ...);-- EMPLOYEES 테이블에서 부서아이디가 10이거나 20번이거나 30번인 직원의 아이디, 이름, 부서아이디를 조회하기 SELECT EMPLOYEE_ID, FIRST_NAME, DEPARTMENT_ID FROM EMPLOYEES WHERE DEPARTMENT_ID = 10 OR DEPARTMENT_ID = 20 OR DEPARTMENT_ID = 30; -- 위의 내용을 IN을 사용해서 나타내기 SELECT EMPLOYEE_ID, FIRST_NAME, DEPARTMENT_ID FROM EMPLOYEES WHERE DEPARTMENT_ID IN (10, 20, 30);- LIKE '패턴'
-> 컬럼의 값이 제시된 패턴과 일치하면 TRUE다.
-> 패턴문자
'%' 0개 이상의 일련의 임의의 문자를 나타낸다. '_' 임의의 문자 하나를 나타낸다. - 이름 LIKE '이_'; 성이 이씨고, 이름이 한 글자인 사람
- 이름 LIKE '이%'; 성이 이씨인 사람
- 책제목 LIKE '%자바%'; 제목에 "자바"가 포함되어 있는 모든 책
SELECT 컬럼명, 컬럼명, .... FROM 테이블명 WHERE 컬럼명 LIKE '%패턴%'
%는 0 OR 무한대
_는 anyone, 무조건 하나가 와야 함
행의 정렬
- order by 절 사용한다.
- order by절은 select문의 맨 마지막에 등장해야 한다.
- where절과 order by절은 생략 가능, select와 from은 생략 불가하다.
SELECT 컬럼명, 컬럼명, .... FROM 테이블명 [where 조건식] [order by {컬럼명|표현식} [ASC|DESC]] -- ASC : 오름차순 정렬 -- DESC : 내림차순 정렬-- EMPLOYEES 테이블에서 50번 부서에 소속된 직원들의 이름, 전화번호, 급여를 조회하기 -- 단, 급여를 오름차순으로 정렬하기 SELECT FIRST_NAME, PHONE_NUMBER, SALARY FROM EMPLOYEES WHERE DEPARTMENT_ID = 50 ORDER BY SALARY ASC; -- EMPLOYEES 테이블의 모든 행을 조회하고, 직원의 아이디, 이름, 직종, 급여, 부서아이디를 조회한다. -- 단, 직종을 오름차순으로 하되, 급여는 내림차순으로 정렬하기 SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID, SALARY, DEPARTMENT_ID FROM EMPLOYEES ORDER BY JOB_ID ASC, SALARY DESC; -- EMPLOYEES 테이블에서 커미션을 받는 직원의 아이디, 이름, 급여, 커미션을 조회하기 -- 단, 커미션을 기준으로 오름차순으로 정렬한다. SELECT EMPLOYEE_ID, FIRST_NAME, SALARY, COMMISSION_PCT FROM EMPLOYEES WHERE COMMISION_PCT IS NOT NULL --(빼먹지 않도록 주의!) ORDER BY COMMISION_PCT ASC;
테이블 생성
-------------------------------------------------------------------------------- -- SAMPLE_USERS 테이블 생성하기 -------------------------------------------------------------------------------- CREATE TABLE SAMPLE_USERS ( -- 컬럼명 데이터타입 제약조건 기본값 USER_ID VARCHAR2(20) PRIMARY KEY, USER_PASSWORD VARCHAR2(20) NOT NULL, USER_EMAIL VARCHAR2(255) NOT NULL UNIQUE, USER_NAME VARCHAR2(100) NOT NULL, USER_TEL VARCHAR2(20), USER_POINT NUMBER(10, 0) DEFAULT 0, USER_DISABLED CHAR(1) DEFAULT 'N', USER_CREATED_DATE DATE DEFAULT SYSDATE, --시스템의 현재 날짜와 시간정보가 저장됨 USER_UPDATED_DATE DATE DEFAULT SYSDATE );- 아이디, 비밀번호, 이메일, 이름에는 반드시 값이 있어야 하지만 전화번호는 선택사항이다.
- SYSDATE는 시스템의 현재 날짜와 시간정보가 저장된다.
- PRIMARY KEY는 반드시 값이 있어야하고, 똑같은 값이 하나도 없어야 한다, 행을 대표하는 값이다.
- UNIQUE는 값이 똑같은게 있으면 안된다.
데이터 추가
- INSERT INTO 명령어 사용
- 한 행씩 추가된다.
- 구문형식
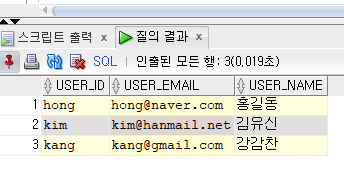
-- 값이 저장될 컬럼명을 직접 나열하는 방식 -- 생략된 컬럼에는 NULL값이 저장된다. 기본값이 있으면 기본값으로 저장된다. INSERT INTO 테이블명 (컬럼명, 컬럼명, 컬럼명) VALUES (값, 값, 값); -- 컬럼명을 생략하는 방식 (권하지 않음) -- 모든 컬럼의 값을 전부 적어야 한다. (기본값이 설정되어 있어도 다 적어야 함) -- 테이블의 컬럼 순서와 동일한 순서로 값을 적어야 한다. INSERT INTO 테이블명 VALUES (값, 값, 값);insert into contacts(name, tel, fax) values('홍길동', '010-1111-111', '02-1111-1111')insert into contacts values('홍길동', '010-1111-111', '서울', 'hong@gmail.com', NULL, sysdate)-------------------------------------------------------------------------------- -- 테이블에 새로운 행 추가하기 -------------------------------------------------------------------------------- INSERT INTO SAMPLE_USERS (USER_ID, USER_PASSWORD, USER_EMAIL, USER_NAME, USER_TEL) VALUES ('hong', 'zxcv1234', 'hong@naver.com', '홍길동', '010-1234-5678'); INSERT INTO SAMPLE_USERS (USER_ID, USER_PASSWORD, USER_EMAIL, USER_NAME) VALUES ('kim', 'zxcv1234', 'kim@hanmail.net', '김유신'); INSERT INTO SAMPLE_USERS (USER_ID, USER_PASSWORD, USER_EMAIL, USER_NAME, USER_TEL, USER_POINT) VALUES ('kang', 'zxcv1234', 'kang@gmail.com', '강감찬', '010-7894-5612', 1000); SELECT USER_ID, USER_EMAIL, USER_NAME FROM SAMPLE_USERS;결과

+) insert, update, delete 작동 방식
데이터베이스관리시스템에는 sql developer 전용의 작업공간, sql plus 전용의 작업공간이 따로 있다.
sql developer에서 sql을 작성하면 전용의 작업공간 안에 있는 내부저장소(메모리)에 데이터가 있으면 거기서 가져온다.
반면에, sql plus는 내부저장소에 아무것도 없으니까 데이터베이스까지 가서 찾는데 커밋을 하지 않으면 테이블에 데이터가 저장되어 있지 않기 때문에 아무것도 나오지 않는다.
COMMIT(커밋)이라는 명령어는 내부저장소에 있는 데이터를 실제로 테이블에 저장되도록 하는 명령어다.
오라클의 데이터 타입
VARCHAR2(size)
- 가변길이 문자 데이터, 최대값 : 4000
- size범위 내에서 실제 데이터의 크기만큼만 저장공간을 사용한다.
- CHAR에 비해 저장속도가 느리다. (실제 데이터 크기에 맞게 저장소의 크기를 조절한 다음에 저장하기 때문)
- 예) 이름, 주소, 과목명, 상품명, 뉴스제목 등
CHAR(size)
- 고정길이 문자 데이터, 최대값 : 2000
- size크기만큼의 저장공간을 무조건 사용한다.
- 예) 주민번호, 학번, 수강과목코드, 국가코드, 우편번호 등 (크기가 항상 고정적인 데이터를 저장할 때 씀)

NUMBER(P, S)
- 가변길이 숫자 데이터
- p: 십진수의 총 갯수, s: 소숫점이하 자릿수
- 예) NUMNER (4,0) : 정수 4자리까지 가능 (-9999~9999까지 가능)
NUMNER (2,2) 전체 2자리인데 소수점 2자리까지 가능하다는 의미 (정수부는 0, 소수점 2자리를 가질 수 있다.)
NUMNER (8,2) 정수부 6자리, 소수부 2자리
DATE
- 날짜 및 시간 데이터
- 예) 입사일, 가입일, 주문날짜, 이체날짜, 신청날짜 ...
ERD (Entity-Relationship Diagram) 개체-관계 다이어그램

- Entitiy들 간의 관계를 표시한다. 관계는 어떤 테이블을 참조하고 있는지를 나타낸다.
- 파란색 글씨는 고유한 값을 가진다. 고유한 값은 중복될 수 없다. 어떤 정보를 대표하는 값은 고유하고 단순할수록 좋다.
- employees테이블의 job_id는 jobs테이블의 job_id 중에 하나다. -> jobs테이블의 job_id를 참조한다.
- JOB_HISTORY의 EMPLOYEE_ID와 START_DATE 2개를 합친게 고유한 값이다. EMPLOYEE_ID 하나로는 고유한 값이 될 수 없다.

- 데이터의 중복을 회피하기 위해서 데이터베이스의 정규화(데이터를 잘게 쪼갬)를 함.
(EMPLOYEES에서는 EMPLOYEE에 대한 정보만 있음. DEPARTMENT의 아이디를 통해 DEPARTMENT에 있는 정보를 찾을 수 있다. (JOIN을 통해서))
- 화면에 정보를 표현할 때 하나의 테이블 안에 있는 정보만 사용하지 않고 보통 2개의 테이블을 연관지어 정보를 가져온다. 연관짓는 것을 JOIN이라고 함.
- 참조당하는 쪽이 부모, 세발표시 되어있는 쪽이 자식테이블임. (어떤 값을 기준으로 했는가에 따라 부모 자식 관계가 달라질 수 있다.)
- 일대 다 관계가 일반적. (부모1 : 자식 多)

- 실선은 부모의 자식이 반드시 있는 것이다. (ORDER_ITEM에 ORDERS의 order_id에 해당하는 자식이 반드시 있는 것임)
- 점선은 자식이 부모의 모든 걸 갖고 있지 않는 것이다. (ORDER_ITEM의 product_id는 모든 PRODUCT INFORMATION의 product_id를 갖고 있지 않음)
'기록' 카테고리의 다른 글
학원 day30. 오라클 내장함수, 데이터 타입 (0) 2022.10.18 학원 day29. 데이터 변경, 삭제, JDBC (0) 2022.10.18 학원 DAY27. 데이터베이스, SQL (0) 2022.10.15 학원 DAY25~26. 예외 처리(2) (0) 2022.10.12 메소드 작성 관련 (0) 2022.10.08